Kubernetes In Action 정리 - 쿠버네티스 내부 이해
- 쿠버네티스 클러스터 구성 요소
- 각 구성 요소의 기능과 동작 방법
- 디플로이먼트 오브젝트를 생성해 파드를 실행하는 방법
- 실행 중인 파드에 관하여
- 파드 간의 네트워크 동작 방식
- 쿠버네티스 서비스의 동작 방식
- 고가용성 실현 방법
11.1 아키텍처 이해
쿠버네티스 클러스터를 이루는 구성
- 쿠버네티스 컨트롤 플레인
- (워커) 노드
컨트롤 플레인 구성요소
- 컨트롤 플레인은 클러스터 기능을 제어 및 전체 클러스터가 동작하게 만드는 역할을 한다. 구성요소는 아래와 같다.
- etcd 분산 저장 스토리지
- API 서버
- 스케줄러
- 컨트롤러 매니저
이들 구성 요소는 클러스터 상태를 저장 및 관리 하지만 애플리케이션 컨테이너를 직접 실행하는 것은 아니다.
워커 노드에서 실행하는 구성요소
- kubelet
- 쿠버네티스 서비스 프록시 (kube-proxy)
- 컨테이너 런타임 (Dockerm rkt …)
애드온 구성요소
컨트롤 플레인과 노드에서 실행되는 구성요소 이외에 몇가지 추가 구성요소가 필요.
- 쿠버네티스 DNS 서버
- 대시보드
- 인그레스 컨트롤러
- 힙스터
- 컨테이너 네트워크 인터페이스 플러그인
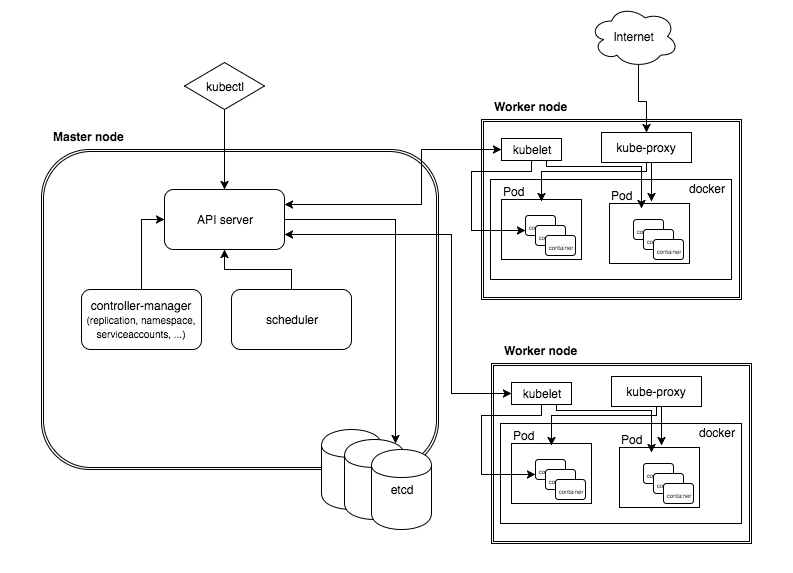
11.1.1 쿠버네티스 구성 요소의 분산 특성
1 | |
구성 요소가 서로 통신하는 방법
쿠버네티스 시스템 구성요소는 오직 API 서버하고만 통신하며 API 서버는 etcd와 통신하는 유일한 구성요소이다.
다른 구성요소는 etcd와 직접 통신하지 않고, API 서버로 클러스터 상태를 변경한다. (API 서버에 요청을 보낸다.)
개별 구성 요소의 여러 인스턴스 실행
워커 노드의 구성요소는 동일한 노드에서 실행되어야 하는 반면 컨트롤 플레인의 구성요소는 여러 서버에 걸쳐 실행 가능하다.
각 컨트롤 플레인 구성 요소 인스턴스를 둘 이상 샐행하여 가용성을 높일 수 있다. (etcd, API 서버는 병렬 실행 가능, 스케줄러와 컨트롤러 매니저는 하나의 인스턴스만 활성화)
구성 요소 실행 방법
Kubelet은 항상 일반 시스템 구성 요소로 실행되는 유일한 구성요소며 Kubelet이 다른 구성 요소를 파드로 실행한다. (kube-proxy와 같은 구성요소는 파드로 실행할 수 있지만 kubelet은 시스템 구성요소(데몬)으로 실행되어야 한다.)
Kubelet 이란 ?
클러스터의 각 노드에서 실행되는 에이전트. Kubelet은 파드에서 컨테이너가 확실하게 동작하도록 관리한다.
Kubelet은 다양한 메커니즘을 통해 제공된 파드 스펙(PodSpec)의 집합을 받아서 컨테이너가 해당 파드 스펙에 따라 건강하게 동작하는 것을 확실히 한다. Kubelet은 쿠버네티스를 통해 생성되지 않는 컨테이너는 관리하지 않는다.
1 | |
컨트롤 플레인의 구성요소는 마스터노드에서 파드로 실행, 세 개의 워커 노드는 kube-proxy와 Flannel 파드를 실행한 오버레이 네트워크를 제공 (Docker K8S에서는 응답값이 다르다.)
11.1.2 쿠버네티스가 etcd를 사용하는 방법
영구적으로 저장되어야 하는 값들을 빠르고 분산하여 저장하기 위하여 일관된 key - value 저장소를 제공한다. 이것이 etcd이다.
분산되어 있기 때문에 둘 이상의 etcd 인스턴스를 실행하여 고가용성과 우수한 성능 제공, 낙관적 잠금 시스템 및 유효성 검사 이점
쿠버네티스가 클러스터 상태와 메타데이터를 저장하는 유일한 장소가 etcd라는 것은 강조할 가치가 있다.
리소스를 etcd에 저장하는 방법
etcd는 파일 시스템과 유사하게 key - value 쌍을 만들어 저장한다. 쿠버네티스는 모든 데이터를 /registry 아래에 저장한다.
1 | |
파드를 나타내는 항목들은 json 형식으로 저장된다.
저장된 오브젝트의 일관성과 유효성 보장
쿠버네티스는 모든 구성 요소가 API 서버를 통하도록 구현하여 데이터가 항상 일치 하도록 구현했다. API 서버 한곳에서 낙관적 잠금 메커니즘을 구현하여 클러스터의 상태를 업데이트 하고,
오류가 발생할 가능성을 줄이고, 일관성을 가질수 있다.
클러스터링된 etcd의 일관성 보장
고가용성을 보장하기 위해 두 개 이상의 etcd 인스턴스를 실행하는것이 일반적.
etcd는 RAFT 합의 알고리즘을 사용하여 어느 순간이든 각 노드 상태가 대다수의 노드가 동의하는 현재 상태이거나, 이전에 동의된 상태 중에 하나임을 보장한다.
합의 알고리즘은 클러스터가 다음 상태로 진행하기 위해 과반수가 필요하다.
etcd 인스턴스 수가 홀수인 이유
etcd는 인스턴스를 일반적으로 홀수로 배포한다. 하나의 인스턴스가 실패하는 경우 과반수의 인스턴스가 필요하기 때문이다.
11.1.3 API 서버의 기능
쿠버네티스 API 서버는 다른 모든 구성 요소와 kubectl 같은 클라이언트에서 사용하는 중심 구성 요소이다.
클러스터 상태를 조회 / 변경하기 위해 RESTful API를 제공한다. 변경된 상태는 etcd에 저장하고 오브젝트 유효성 검사 작업도 수행하기 때문에 잘못 설정된 오브젝트를 저장할 수 없다.
API 서버의 클라이언트 중 하나는 kubectl 명령줄 도구이다.
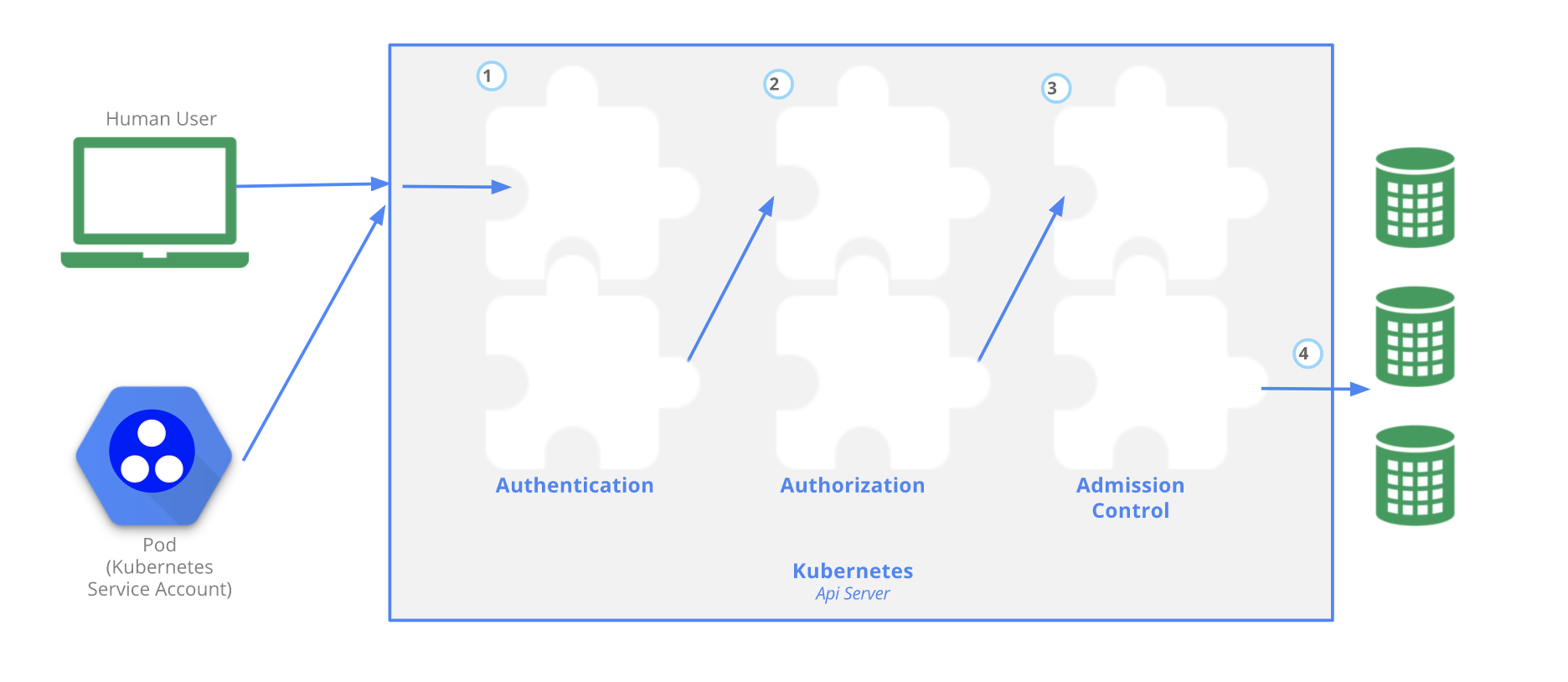
인증 플러그인으로 클라이언트 인증
인증 방법에 따라 사용자를 클라이언트 인증서 혹은 HTTP 헤더에서 가져온다. 플러그인은 클라이언트의 사용자 이름, 사용자 ID, 속해있는 그룹 정보 추출
인가 플러그인을 통한 클라이언트 인가
API 서버는 하나 이상의 인가 플러그인을 사용하도록 되어 있다. 인증된 사용자가 요청한 작업이 수행 가능한 권한이 있는지를 판별
ex) 파드를 생성할 때 API 서버는 모든 인가 플러그인을 호출하여 사용자가 요청한 네임스페이스안에 파드를 생성 할 수 있는지 결정
어드미션 컨트롤 플러그인으로 요청된 리소스 확인과 수정
리소스를 생성, 수정, 삭제 하려는 요청인 경우 어드미션 컨트롤로 보내진다. 이 플러그인은 리소스를 여러가지 이유로 수정할 수 있다. 리소스 정의에서 누락된 필드를 기본값으로 초기화 하거나 재정의 가능하다.
- AlwaysPullImages : 파드의 imagePullPolicy를 Always로 변경하여 파드가 배포될 때 마다 이미지를 항상 강제로 가져오도록 재정의.
- ServiceAccount : 명시적으로 지정하지 않을 경우 default 서비스 어카운트를 적용
- NamespaceLifecycle : 삭제되는 과정에 있는 네임스페이스와 존재하지 않는 네임스페이스 안에 파드가 생성되는것을 방지
- ResourceQuota : 특정 네임스페이스 안에 있는 파드가 해당 네임스페이스에 할당된 CPU와 메모리만을 사용하도록 강제한다.
리소스 휴효성 확인 및 영구 저장
요청이 모든 어드미션 컨트롤 플러그인을 통과하면, API 서버는 오브젝트의 유효성을 검증하고 etcd에 저장한다.
11.1.4 API 서버가 리소스 변경을 클라이언트에 통보하는 방법 이해
API 서버는 우리가 논의했던 것 외에 다른 아무것도 하지 않는다. API 서버는 컨트롤러에 무엇을 해야하는지 알려주지 않고 컨트롤러와 다른 구성 요소가 배포된 리소스의 변경사항을 관찰 할 수 있게 한다.
컨트롤 플레인 구성 요소는 리소스가 생성, 수정, 삭제 될 떄 통보를 받을 수 있도록 요청할 수 있다.
클라이언트는 API 서버에 HTTP 연결을 맺고 변경사항을 감지한다. 오브젝트가 변경되거나 갱신될 때 마다 서버는 연결된 모든 클라이언트에게 오브젝트의 새로운 버전을 보낸다.
kubectl 도구를 사용하여 리소스 변경을 감시할 수 있다. 새로운 버전의 pod을 배포 하고, kubectl get pod -w 실행하면 감시 이벤트를 받을수 있다.
11.1.5 스케줄러의 이해
일반적으로 파드를 실행할 때 클러스터 노드를 지정하지 않는 것을 알고 있다. 이것은 스케줄러에게 맡겨진 일이다. API 서버의 감시 메커니즘을 통해 새로운 파드가 생성되면 적절한 노드에게 파드를 할당한다.
스케줄러는 선택된 노드에 파드를 실행하도록 지시 하지 않고 API 서버로 파드 정의를 갱신, API 서버는 kubelet에 새로운 파드가 스케줄링된것을 통보한다. 대상 노드의 kubelet이 파드의 컨테이너를 생성하고 실행한다.
기본 스케줄링 알고리즘의 이해
- 모든 노드 중에서 파드를 스케줄링할 수 있는 노드 목록을 필터링
- 수용 가능한 노드의 우선순위를 정하고 점수가 높은 노드를 선택, 점수가 같은 경우 라운드 로빈을 사용
수용 가능한 노드 찾기
파드를 수용할 수 있는 노드를 찾기 위해 아래 조건들을 검사한다.
- 노드가 하드웨어 리소스에 대한 파드 요청을 충족 시킬수 있는가 ?
- 노드에 리소스가 부족한가
- 파드를 특정 노드로 스케줄링하도록 요청한 경우 해당 노드인지 판별
- 노드가 파드 정의 안에 있는 노드 셀렉터와 일치하는 레이블을 가지고 있는가 ?
- 파드가 특정 호스트 포트에 할당 되도록 요청한 경우 해당 포트가 이 노드에서 이미 사용중인가 ?
- 파드 요청이 특정한 유형의 볼륨을 요청하는 경우 이 노드에서 해당 볼륨을 파드에 마운트 할 수 있는가, 아니면 이 노드에 있는 다른 파드가 이미 같은 볼륨을 사용하는가 ?
- 파드가 노드의 테인트를 허용하는가 ?
- 파드가 노드와ㅏ 파드의 어피니티, 안티 어피니티 규칙을 지정했는가 ?
파드에 가장 적합한 노드 선택
두 개의 노드로 구성된 클러스터에서 A 노드가 10개의 파드를 실행, B 노드가 0개의 파드를 실행하고 있는 경우 새로운 파드는 B에 할당 될 것 이지만, A에 할당하여 B 노드를 반환하고 비용을 절감 시키는 방법도 있다. 이러한 판단은 스케줄러가 해주지 않는다.
고급 파드 스케줄링
파드의 레플리카가 여러개인 경우 한 노드에 스케줄링하는것 보다 많은 노드에 분산 시키는것이 효과적이다. 동일한 서비스 또는 레플리카셋에 속한 파드는 기본적으로 여러 노드에 분산된다.
다중 스케줄러 사용
클러스터에서 여러개의 스케줄러를 실행할 수 있다. 파드 정의 안에 schedulerName속성에 파드를 스케줄링할 스케줄러를 지정할 수 있다. 속성을 지정하지 않을 경우 default-scheduler를 사용하여 스케줄링 된다.
사용자가 직접 스케줄러를 구현하여 클러스터에 배포하거나, 다른 설정 옵션을 가진 쿠버네티스의 스케줄러를 배포할 수도 있다.
11.1.6 컨트롤러 매니저에서 실행되는 컨트롤러 소개
API 서버는 리소스를 etcd에 저장하고 변경사항을 클라이언트에 통보한다. 스케줄러는 파드를 노드에 할당만 한다. API 서버에 배포된 리소스에 지정된 대로 시스템을 원하는 상태로 수렴되도록 하는 역할은 컨트롤러 매니저 안에서 실행되는 컨트롤러에 의해 수행된다.
- 레플리케이션 매니저
- 레플리카셋, 데몬셋, 잡 컨트롤러
- 디플로이먼트 컨트롤러
- 스테이트풀셋 컨트롤러
- 노드 컨트롤러
- 서비스 컨트롤러
- 엔드포인트 컨트롤러
- 네임스페이스 컨트롤러
- 퍼시스턴트볼륨 컨트롤러
- …
리소스는 클러스터에 어떤 것을 실행해야 하는지 기술하는 반면, 컨트롤러는 리소스를 배포함에 따라 실제 작업을 수행하는 활성화된 쿠버네티스 구성 요소이다.
컨트롤러의 역할과 동작 방식 이해
컨트롤러는 다양한 작업을 수행하지만 API 서버에서 리소스 변경을 감지, 변경 작업을 수행한다. 일반적으로 컨트롤러는 조정 루프를 실행하여 리소스의 spec에 정의된 상태를 유지하려고 한다. 컨트롤러는 API 서버에 연결하고 감시 메커니즘 컨트롤러가 담당하는 리소스 유형에서 변경이 발생하면 통보 해줄것을 요청한다.
레플리케이션 매니저
레플리케이션컨트롤러 리소스를 활성화 하는 컨트롤러를 레플리케이션 매니저라고 한다. 컨트롤러는 파드 셀렉터와 일치하는 파드의 수를 찾고 이를 원하는(spec에 정의된) 레플리카 수와 비교한다. 레플리카 수가 적거나 많으면 새로운 레플리케이션 매니저는 새로운 파드 매니페스트를 생성하여 API 서버에 게시하고 스케줄러와 kubelet이 작업을 수행한다.
레플리카셋, 데몬셋, 잡 컨트롤러
레플리카셋 컨트롤러는 레플리케이션 매니저와 거의 동일한 기능을 수행, 데몬셋, 잡 컨트롤러는 파드 리소스를 생성한다.
디플로이먼트 컨트롤러
디플로이먼트 컨트롤러는 실제 배포된 상태와 디플로이먼트 API 오브젝트에 기록된 원하는 상태가 동기화되도록 관리한다.
스테이트풀셋 컨트롤러
스테이트풀셋 컨트롤러는 리소스 정의에 따라 파드를 관리, 다른 컨트롤러와의 차이점은 퍼시스턴트 볼륨 클레임도 관리한다는것이다.
노드 컨트롤러
클러스터의 워커 노드를 기술하는 노드 리소스를 관리, 클러스터에서 실행 중인 실제 머신 목록과 노드 오브젝트 목록을 동기화하는 데 중점을 둔다.
서비스 컨트롤러
로드밸런서 유형의 서비스가 생성되거나 삭제 되는 경우 인프라스트럭처에 로드밸런서를 요청하고 해제하는 역할 수행
엔드포인트 컨트롤러
서비스는 파드에 직접 연결되어 있지는 않지만 서비스에 정의된 파드 셀렉터에 따라 엔드포인트(ip, port)를 포함한다. 레이블 셀렉터와 일치하는 파드의 IP와 포트로 엔드포인트 리스트를 계속 갱신하는 활성 구성요소이다.
네임스페이스 컨트롤러
퍼시스턴트볼륨 컨트롤러
퍼시스턴트볼륨 클레임과 퍼시스턴트 볼륨을 연결하는 역할.
컨트롤러 정리
컨트롤러는 API 서버로 API 오브젝트를 제어한다. 모든 컨트롤러는 kubelet과 직접 통신하거나 어떤 요청도 하지 않는다.
컨트롤 플레인은 쿠버네티스 운영의 한 부분만 처리하기 때문에 내부 동작을 이해하기 위해선 kubelet과 쿠버네티스 서비스 프록시를 이해해야한다.
11.1.7 Kubelet이 하는 일
쿠버네티스 컨트롤 플레인의 일부로 Kubelet과 서비스 프록시는 워커 노드에서 실행된다.
Kubelet의 작업 이해
Kubelet은 워커 노드에서 실행하는 모든것을 담당하는 요소이다. Kubelet이 실행 중인 노드를 노드 리소스로 만들어 API 서버에 등록하여 API 서버를 모니터링 하여 스케줄링 이벤트를 처리한다. 또한 컨테이너를 게속 모니터링 하며 상태, 이벤트, 리소스 사용량 등을 API 서버에 보고한다. Kubelet은 컨테이너 라이브니스 프로브를 실행하는 요소이기도 하며 프로브가 실패할 경우 컨테이너를 재시작 한다. 마지막으로 API 서버에서 파드가 삭제되면 컨테이너를 정지하고 파드가 종료된것을 서버에 통보한다.
API 서버 없이 정적 파드 실행
Kubelet은 쿠버네티스 API 서버와 통신하여 파드 매니페스트를 가져오지만 특정 로컬 디렉토리안에 있는 매니페스트 기반으로 파드를 실행할 수 있다. 시스템 구성 요소 파드 매니페스트를 Kubelet의 매니페스트 디렉토리에 넣어 Kubelet이 관리 하도록 할 수 있다. 사용자 정의 컨테이너는 데몬셋을 활용하는 것을 추천한다.
쿠버네티스 서비스 프록시의 역할
모든 워커 노드는 클라이언트가 쿠버네티스 API로 정의한 서비스에 연결할 수 있도록 해주는 kube-proxy도 실행된다. kube-proxy는 서비스로 들어온 요청을 서비스를 지원하는 파드 중 하나로 연결해준다.
서비스가 둘 이상의 파드에서 지원되는 경우 프록시는 로드밸런싱을 수행.
프록시라고 부르는 이유
kube-proxy는 실제 프록시 이지만 현재는 iptables 규칙만 사용하여 프록시 서버를 거치지 않는다고 한다. 커널에서 요청을 처리하기 때문에 성능상 이점이 있다.
11.1.9 쿠버네티스 에드온 소개
애드온 배포 방식
애드온은 yaml 매니페스트를 API 서버에 게시해 파드로 배포된다.
1 | |
DNS 서버 동작 방식
파드는 기본적으로 클러스터 내부 DNS 서버를 사용하도록 설정되어 있다. DNS 서버 파드는 kube-dns 서비스로 노출되며 해당 서비스의 ip 주소는 클러스터에 배포된 모든 컨테이너가 가지고 있는 /etc/resolv.conf 파일안에 nameserver로 지정되어 있다. kube-dns 파드는 API 서버를 통해 서비스와 엔드포인트의 변화를 관절하고 갱신한다.
인그레스 컨트롤러 동작 방식
인그레스 컨트롤러는 리버스 프록시 서버(nginx)를 실행하고 클러스터에 정의된 인그레스, 서비스, 엔드포인트 리소스 설정을 유지한다. 컨트롤러는 이러한 리소스를 감시하고 변경한다.
인그레스 컨트롤러는 트래픽을 서비스의 IP로 전달하지 않고 서비스의 파드로 전달한다.
11.2 컨트롤러가 협업하는 방법
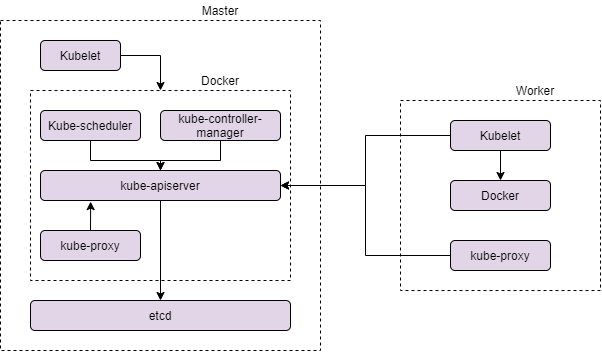
11.2.1 관련된 구성 요소 이해
컨트롤러와 스케줄러, Kubelet은 API 서버에서 각 리소스 유형이 변경되는 것을 감지한다.
11.2.2 이벤트 체인
디플로이먼트 매니페스트를 가진 YAML파일을 배포하는 경우 kubectl은 매니페스트를 API 서버에 전송, API 서버는 매니페스트를 검증하고 etcd에 저장한 뒤 응답한다.
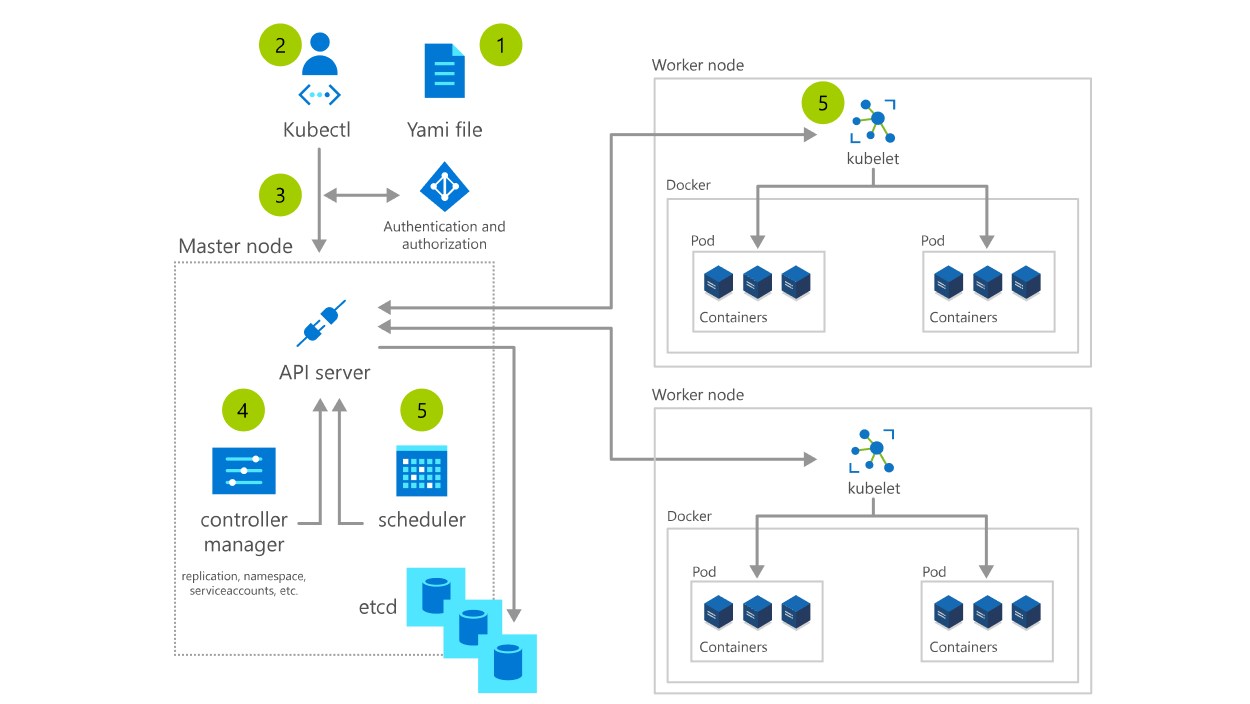
디플로이먼트 컨트롤러가 레플리카셋 생성
디플로이먼트 컨트롤러는 디플로이먼트를 담당하는 활성 구성요소이며 새로운 리소스가 감지되면 현재 디플로이먼트 정의를 이용하여 레플리카셋을 생성한다.
레플리카셋 컨트롤러가 파드 리소스 생성
레플리카셋 컨트롤러는 새롭게 생성된 레플리카셋을 낚아채 정의된 파드 수와 파드 셀렉터와 일치하는 실행중인 파드가 충분한지 확인, 파드 템플릿 기반으로 파드 리소스를 생성한다.
스케줄러가 새로 생성한 파드에 노드 할당
생성된 파드는 etcd에 저장되며 아직 노드가 할당 되지 않은 상태 (nodename 속성이 안되어있다.)이다. 스케줄러는 파드를 감시하며 적절한 노드에 파드를 배치하는 역할을 한다.
Kubelet은 파드의 컨테이너를 실행한다
파드가 특정 노드로 스케줄링되면 해당 노드의 Kubelet이 동작하여 도커 또는 사용중인 컨테이너 런타임에 파드의 컨테이너를 시작하도록 지시한다.
11.2.3 클러스터 이벤트 관찰
컨트롤 플레인 구성 요소와 Kubelet은 이러한 작업을 수행시 API 서버로 이벤트를 발송한다.
1 | |
11.3 실행 중인 파드에 관한 이해
Kubelet은 하나의 파드를 실행한고 해서 컨테이너 하나만 실행하지 않는다. 어플리케이션 컨테이너는 종료되고 다시 시작 될 수 있으므로 이런 컨테이너가 이전과 동일한 리눅스 네임스페이스 일부가 되어야 하기 때문에 인프라스트럭처 컨테이너와 같이 실행된다. 인프라스트럭처 컨테이너가 그 중간에 종료되는 경우 kubelet이 인프라스트럭처와 파드의 모든 컨테이너를 재생성한다. (현재도 동일한지 확인필요.)
1 | |
11.4 파드 간 네트워킹
11.4.1 네트워크는 어떤 모습이어야 하는가
쿠버네티스는 특정 네트워크 기술을 사용하는걸 요구하지는 않지만 파드간(컨테이너간) 통신할 수 있어야 한다. 파드가 통신하는데 사용하는 네트워크는 파드가 보는 자신의 IP 주소가 모든 다른 파드에서 해당 파드를 찾을떄 해당 IP 주소로 찾을 수 있어야 한다.
NAT가 없는 경우 파드A에서 파드B로 패킷을 전송할 때 출발지와 목적지 주소가 변경되지 않은 상태로 도작해야 한다. 파드 사이에 NAT가 없으면 내부에서 실행중인 어플리케이션이 다른 파드에 자동으로 등록 될 수 있다.
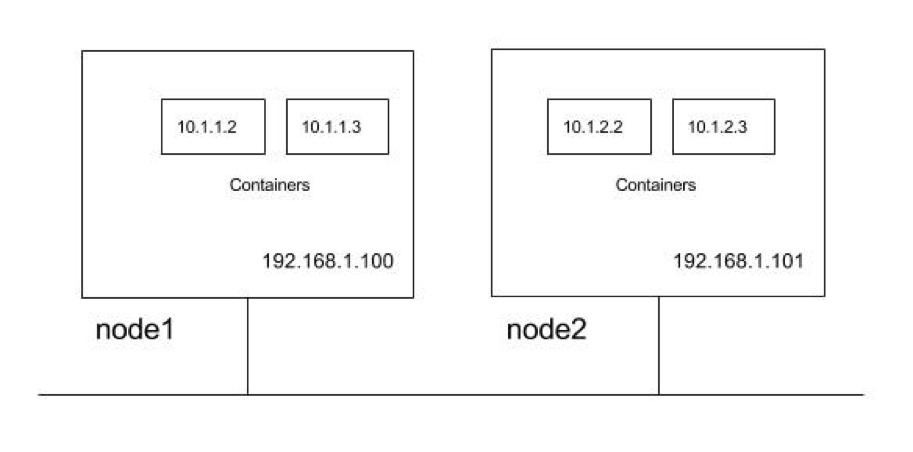
하지만 파드가 인터넷에 있는 서비스와 통신하는 경우 패킷의 출발지 IP를 변경하는 것이 필요하다. 파드의 IP는 사설IP 이기 때문이며 외부로 나가는 패킷의 출발지 IP는 호스트 워커 노드의 IP로 변경된다.
11.4.2 네트워킹 동작 방식 자세히 알아보기
파드의 네트워크 인터페이스는 인프라스트럭처 컨테이너에서 설정한다.
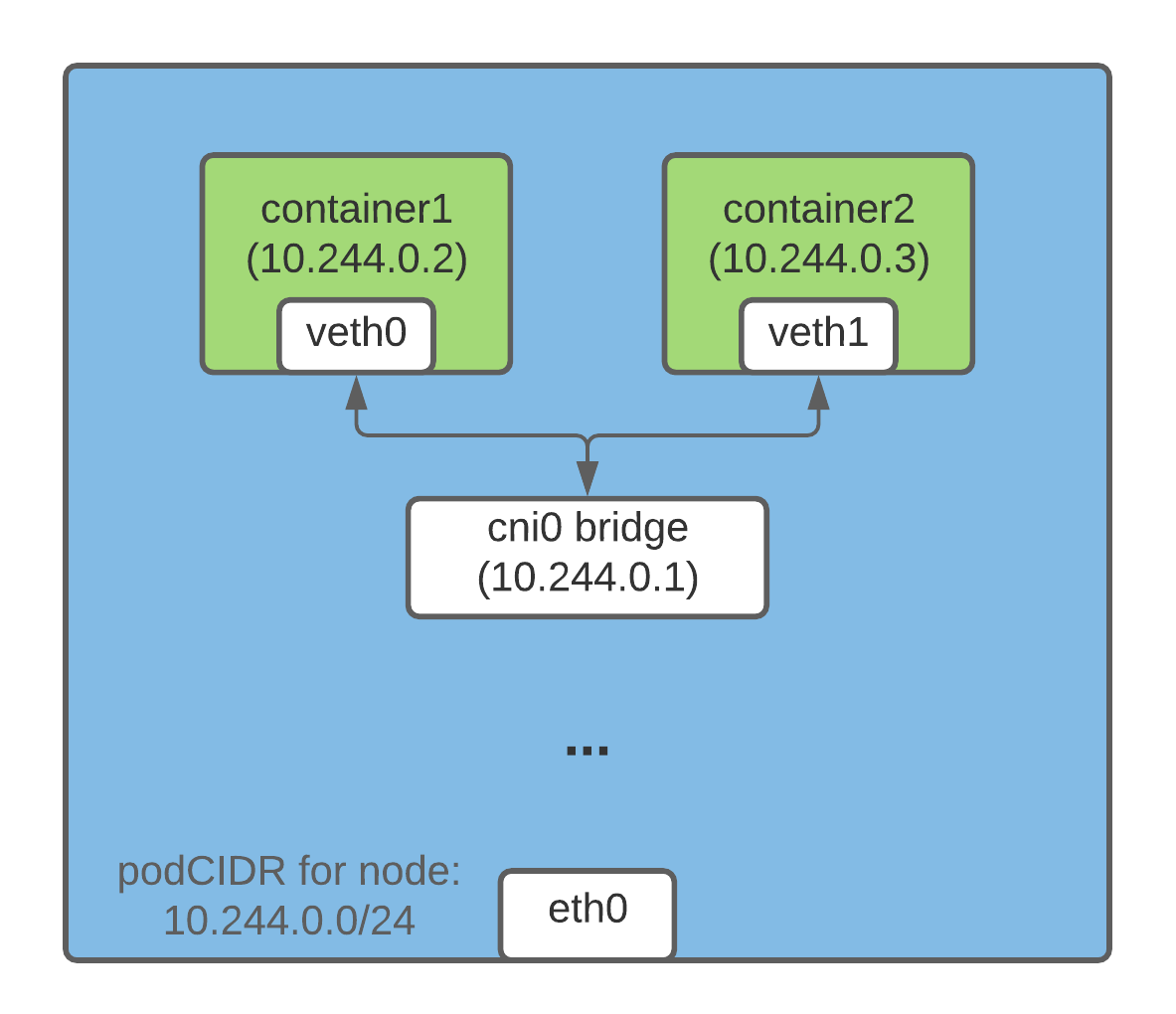
동일한 노드에서 파드 간의 통신 활성화
인프라스트럭처 컨테이너가 시작되기전 컨테이너를 위한 가상 이더넷 인터페이스 쌍이 생성. 한쪽은 호스트의 네임스페이스에 남고, 다른쪽은 컨테이너 네트워크 네임스페이스안으로 이동하여 eth0로 변경된다.
호스트의 네트워크 네임스페이스에 있는 인터페이스는 컨테이너 런타임이 사용할 수 있는 네트워크 브리지에 연결되고 컨테이너 안의 eth0 인터페이스는 브리지의 주소 범위 안에서 IP를 할당 받는다.
어플리케이션에서 eth0 인터페이스로 요청을 보내면 veth 인터페이스로 나와 브리지로 전달된다.
파드 A 에서 B로 패킷을 보내는 과정은 A의 veth 쌍을 통해 브리지로 전달되고 B의 veth 쌍을 통과한다. 노드에 있는 모든 컨테이너는 같은 브리지에 연결되어 있기 때문에 서로 통신이 가능하다.
서로 다른 노드에서 파드 간의 통신 활성화
파드 IP주소는 클러스터 내에서 유일해야 하기 때문에 노드 사이의 브리지는 겹치지 않는 주소 범위를 사용한다.

위 그림은 일반 계층 3 네트워킹으로 노드간 통신을 하려면 노드의 물리 네트워크 인터페이스도 브리지에 연결해야 하는것을 보여준다. 이러한 유형은 패킷을 다른 노드에 있는 컨테이너로 보낼 때 패킷이 먼저 veth 쌍을 통과한 다음 브리지를 통해 노드의 물리 어댑터로 전달된다. 그 후 물리회선과 다른 노드의 브리지를 지나 패킷이 전송된다. 이러한 방식은 노드가 많아지고 라우터를 사용한다면 라우터의 갯수도 많아지며 오류가 발생할 여지가 늘어나기 때문에 소프트웨어 정의 네트워크 방식을 사용하는것이 더 쉽다. SDN을 이용하면 네트워크 구조가 복잡해지더라도 노드들이 같은 네트워크에 연결된것으로 볼 수 있어 패킷이 캡슐화 되어 다른 파드로 전달할 수 있다.
11.4.3 컨테이너 네트워크 인터페이스 소개
컨테이너를 네트워크에 쉽게 연결하기 위해, 컨테이너 네트워크 인터페이스(CNI)가 시작됬다.
- Calico
- Flannel
- Romana
- Weave Net
- etc
11.5 서비스 구현 방식
서비스는 파드 집합을 길게 지속되는 안정적인 IP와 포트로 노출 시키는역할을 한다.
11.5.1 kube-proxy 소개
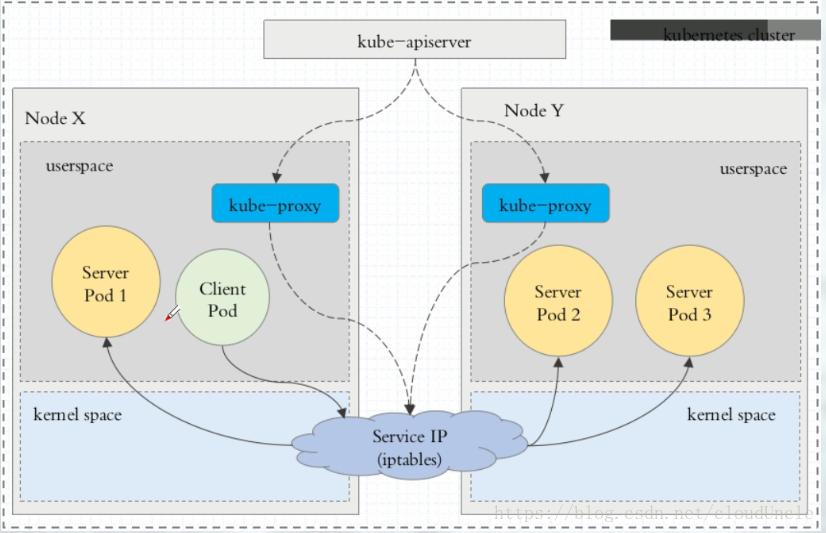
서비스와 관련된 모든 동작은 kube-proxy를 통해 이루어진다. 초기엔 kube-proxy가 실제 프록시로 동작했지만 현재는 iptables 프록시 모드를 사용한다. 서비스는 안정적인 IP 주소와 포트를 얻고 클라이언트는 그 정보를 활용하여 접근한다. 서비스의 주요 핵심은 서비스가 IP와 포트의 쌍으로 구성된다는것과 서비스 IP만으로는 아무것도 나타내지 않는다는것이다.
11.5.2 kube-proxy가 iptables를 사용하는 방법
API 서버에서 서비스를 생성하면 IP 가 할당되고 워커 노드에서 실행중인 kube-proxy 에이전트에 알린다. 각 kube-proxy는 실행중인 노드에 해당 서비스 주소로 접근 할 수 있도록 만든다. 이러한 과정은 서비스의 ip/port 쌍으로 향하는 패킷을 가로채 목적지 주소를 변경하여 패킷이 서비스를 지원하는 여러 파드 중 하나로 리디렉션 되도록 하는 iptables 규칙을 설정함으로 이루어지는 것이다.
kube-proxy는 API서버에서 서비스가 변경되는것을 감지하는것 이외에도 엔드 포인트 오브젝트가 변경되는것을 감시한다. 파드가 생성, 삭제 되거나 요청을 받지 못하는 상태가 되면 엔드 포인트 오브젝트가 변경된다.
11.6 고가용성 클러스터 실행
서비스를 중단 없이 사용하기위하여 쿠버네티스 컨트롤 플레인 구성요소에 대해 알아보자.
11.6.1 어플리케이션 가용성 높이기
다양한 컨트롤러는 노드에 장애가 발생하여도 원할하게 동작할 수 있도록 도와준다. 어플리케이션의 가용성을 높이기 위해선 디플로이먼트 실행과 적잘한 레플리카 수만 할당해주면 되고, 나머지는 쿠버네티스가 알아서 해준다.
가동 중단 시간을 줄이기 위한 다중 인스턴스 실행
가동 중단 시간을 줄이기 위해선 어플리케이션을 수평으로 확장할 수 있는 구조가 되어야 한다. 그렇지 못하더라도 레플리카 수를 1로 설정한 디플로이먼트를 사용하여 장애가 일어나더라도 빠르게 복구 될 수 있도록 대비해야 한다.
수평 스케일링이 불가능한 어플리케이션을 위한 리더 선출 메커니즘 사용
활성 복제본과 비활성 복제본을 실행하여 빠른 임대 혹은 리더 선출 메커니즘을 이용하여 하나만 활성 상태로 만들 수 있다. 리더 선출 방식은 여러가지가 있는데, 리더가 작업에 실패하면 다른 인스턴스가 리더가 될 수 있고 리더만 쓰기를 하고 나머지는 읽기만 하는 기능을 제공할 수도 있다.
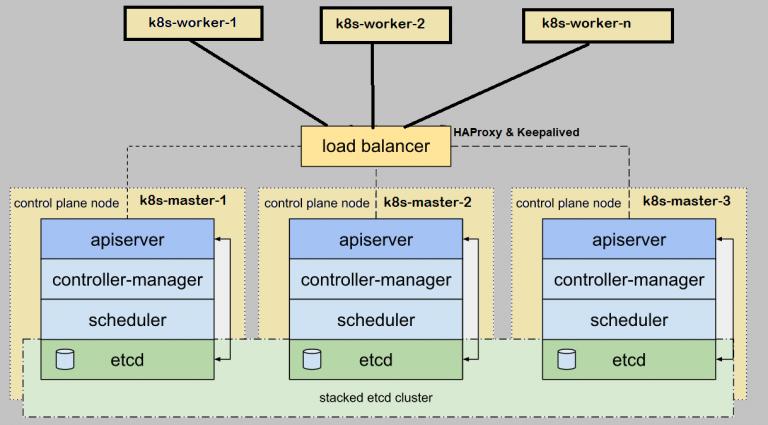
11.6.2 쿠버네티스 컨트롤 플레인 구성 요소의 가용성 확장
쿠버네티스의 가용성을 높이기 위해 컨트롤 플레인을 구성하는 요소의 인스턴스들을 마스터 노드에서 실행해야 한다.
- etcd
- API 서버
- 컨트롤러 메니저
- 스케줄러
etcd 클러스터 실행
etcd는 분산 시스템으로 설계되어 가용성을 높이는 것은 큰 문제가 되지 않음. 필요한 수의 인스턴스를 실행하고 서로를 인식할 수 있게 하면 된다.
etcd는 모든 인스턴스에 걸쳐 데이터를 복제 하기 때문에 한 노드가 슬패하더라도 읽기, 쓰기 잡업을 수행 할 수 있다. 7대 이상의 etcd 인스턴스가 필요한 경우는 거의 없으며 오히려 성능에 영향을 미칠 수 있다.
여러 API 서버 인스턴스 실행
API 서버의 가용성을 높이는 일은 더 간단하며 API 서버는 stateless한 상태 이기에 필요한 만큼 실행하면 된다. 일반적으로 etcd 인스턴스에 API 서버를 같이 띄운다. 이러한 구조일 경우 모든 API 서버가 로컬에 있는 etcd인스턴스와 통신하기 때문에 etcd 인스턴스 앞에 로드 밸런서를 둘 필요가 없고 API 서버는 로드 밸런서가 앞에 위치 하기 때문에 항상 정상적인 API 서버와 통신하게 된다.
컨트롤러와 스케줄러의 고가용성 확보
컨트롤러 매니저나 스케줄러의 여러 인스턴스를 동시에 실행하는것은 쉽지 않다. 컨트롤러와 스케줄러는 클러스터 상태를 감시하고 상태가 변경될때 요청을 보내야 하는데 한번에 요청에 여러 인스턴스가 서로 경쟁하여 원하지 않은 결과가 발생할 수 있다. 이러한 이유 때문에 컨트롤러 매니저나 스케줄러는 하나의 인스턴스만 활성화 하도록 되어 있다.
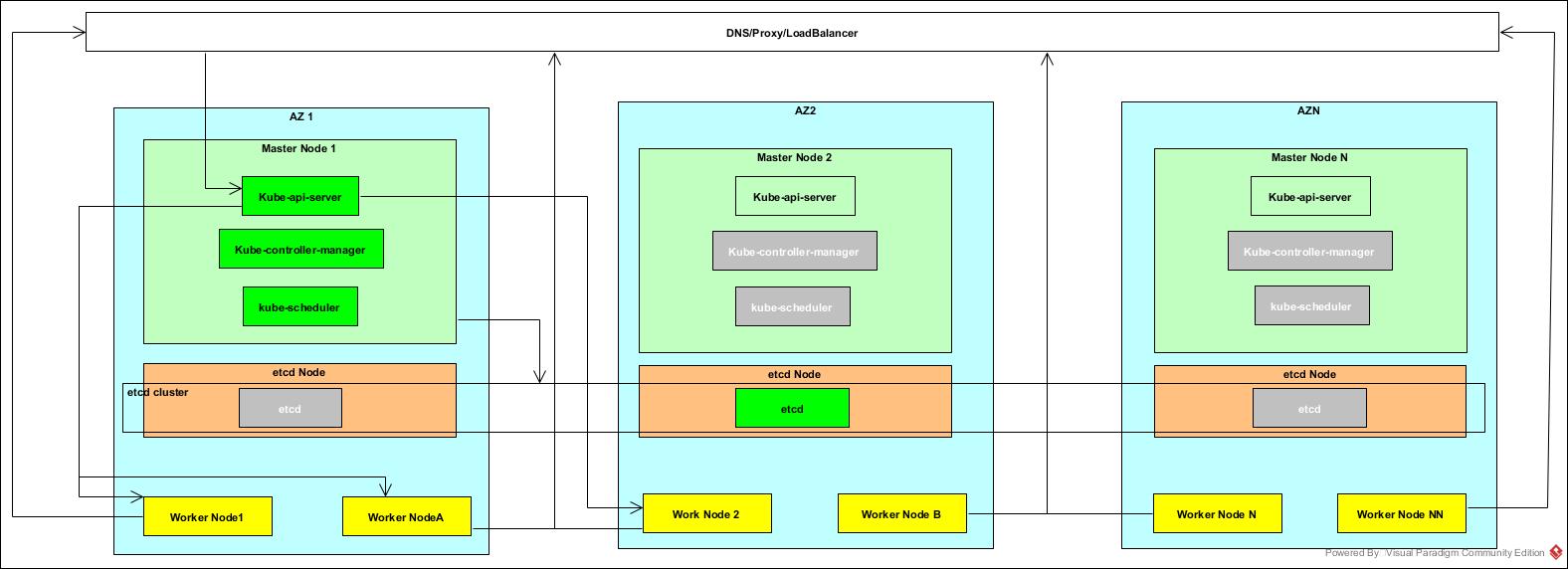 컨트롤러 매니저와 스케줄러는 API 서버 그리고 etcd와 같이 실행되거나 다른 머신에서 실행 가능하다. 같이 실행될 경우 로컨 API 서버와 통신하고 다른 머신에서 실행될 경우 로드밸런서를 통한다.
컨트롤러 매니저와 스케줄러는 API 서버 그리고 etcd와 같이 실행되거나 다른 머신에서 실행 가능하다. 같이 실행될 경우 로컨 API 서버와 통신하고 다른 머신에서 실행될 경우 로드밸런서를 통한다.
컨트롤 플레인 구성 요소에서 사용되는 리더 선출 메커니즘 이해
리더 선출 메커니즘은 API 서버에 오브젝트를 생성하는것으로 완벽히 동작한다. 특별한 리소스를 사용하는것도 아니며 엔드포인트 리소스를 사용한다.
1 | |
control-plane.alpha.kubernetes.io/leader 를 보면 리더의 이름을 가지고 있는 holderIdentity 필드가 있다. 해당 필드에 등록된 인스턴스가 리더가 된다.
- 이미지 출처
- https://www.aquasec.com/cloud-native-academy/kubernetes-101/kubernetes-architecture/
- https://kubernetes.io/ko/docs/concepts/security/controlling-access/
- https://velog.io/@pingping95/Kubernetes-Architecture
- https://azure.microsoft.com/ko-kr/overview/kubernetes-deployment-strategy/
- https://superuser.openstack.org/articles/review-of-pod-to-pod-communications-in-kubernetes/
- https://ronaknathani.com/blog/2020/08/how-a-kubernetes-pod-gets-an-ip-address/
- https://www.programmersought.com/article/740343148/
- https://www.programmersought.com/article/32457245519/
- https://www.suse.com/c/kubernetes-cluster-vs-master-node/